
Introduction: Why WMS Breakdowns Still Happen in Modern Warehouses
A warehouse management system is a control layer. It tells people, robots, and machines where to move and when. In practice, a wms system should make flow smooth. Yet many sites still choke during peak hours. Picture a regional distributor on a Sunday night close. Orders spike by 28%. Dock doors queue. Pallets stack in the wrong aisle. Then a single mis-scan delays three routes—funny how that works, right? Data shows small errors compound fast: a 1.8% pick error can add 14% to rework time. Now, dear reader, let us ask: is the issue the process, or the software pattern behind it?
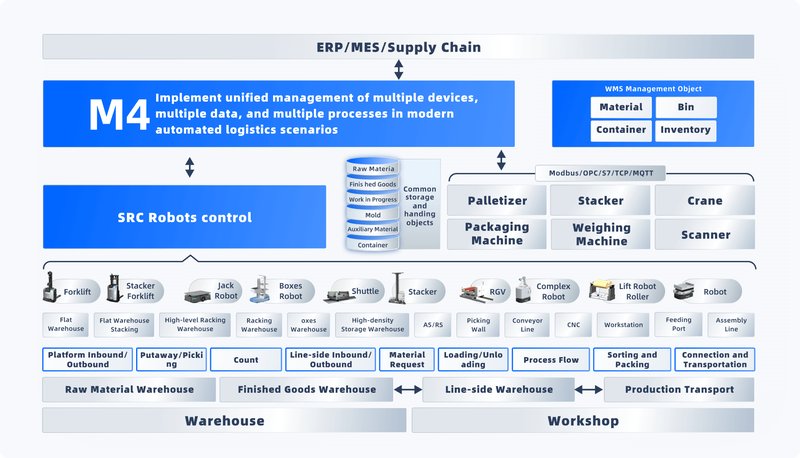
Where do the cracks appear?
Building on Part 1, we go deeper into traditional solution flaws. Many legacy designs assume batch updates. They post inventory at fixed intervals, not in real time. That creates blind spots between scan and system truth. Old stacks bind scanners, carriers, and ERP in tight couplings. When one device lags, all wait. There is often a slow “message queue” with no back-pressure strategy. “RFID middleware” runs in a corner server with little observability. And edge computing nodes are absent, so every barcode ping must round-trip to the data center. Look, it’s simpler than you think: latency becomes lost minutes, and lost minutes become missed SLAs. Add manual exception handling, static slotting, and brittle ASN checks, and you get fire drills. The logistics management system you hoped would guide flow now blocks it (unintentionally). The question is how to unwind these bottlenecks and replace them with adaptive control—let us move there now.

Comparative Insight: New Principles That Outrun Old Conventions
Part 2 highlighted the path from events to KPIs. Here we compare the how. Old designs batch, push, and wait. New designs stream, sense, and decide. A modern wms system favors event-driven logic with lightweight services. It routes signals to the closest compute, not a distant core. That means edge decisions for putaway, task assignment, and dock sequencing. A “digital twin” tracks assets and lanes in near real time. It updates when a pallet turns left, not when a nightly job runs. Telemetry fuels simple forecasts, like “Door 3 stalls in 12 minutes unless we shift labor.” And when AMR fleet orchestration meets human pickers, the plan adjusts on the fly— and yes, the forklift battery will die exactly then. The shift is not hype. It is smaller payloads, faster feedback, and graceful failure when a sensor hiccups.
What’s Next
So what do we carry forward? First, replace brittle chains with resilient loops. That means short cycles, local fallbacks, and clear observability. Second, compare alternatives by what they do under stress, not in a demo. Third, choose metrics that expose delay, not just totals. Advisory close: use three tests when you assess any platform. 1) Latency under load: median and tail times for task creation, pick confirm, and dock release during peak. 2) Degradation behavior: how the system routes around a dead scanner or a downed subnet without losing inventory truth. 3) Adaptation speed: minutes to learn and re-slot when demand shifts by 20% for a SKU family. If a tool scores well here, it will likely tame the queues, reduce rework, and steady your promise dates. For neutral, engineering-focused reading, see SEER Robotics.

